Seed Audio
Seed Audio - KI-Tool für Text-to-Speech und Dialoggenerierung

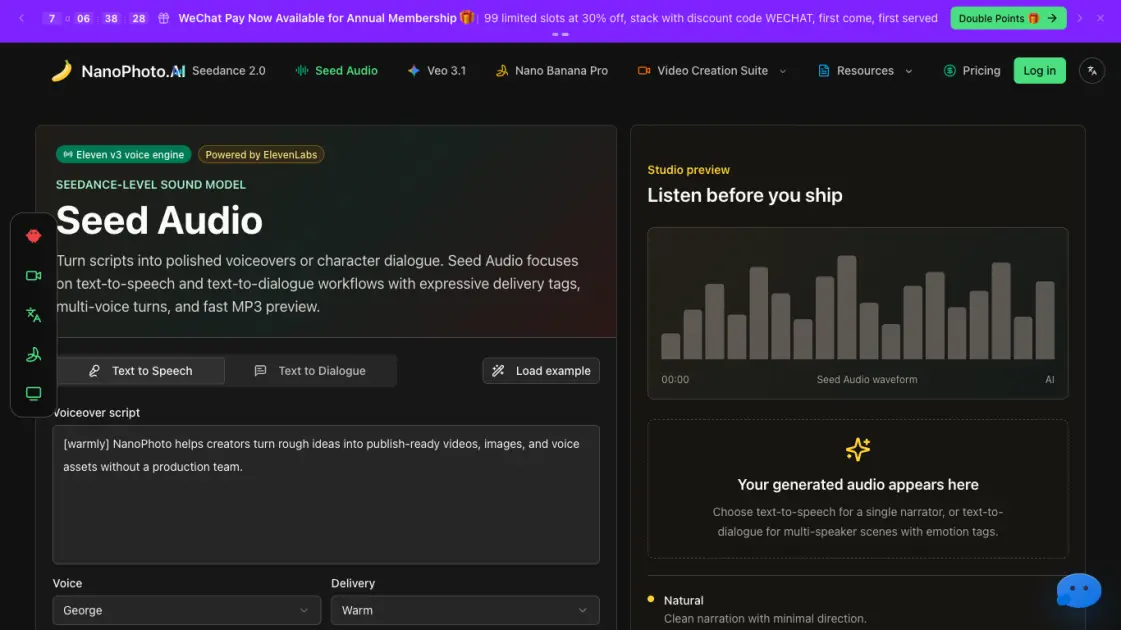
Was ist Seed Audio
Seed Audio ist ein Text-to-Speech- und Dialoggenerierungstool, das auf der ElevenLabs-Infrastruktur basiert und über die NanoPhoto-Plattform zugänglich ist. Der Dienst wandelt geschriebene Skripte in MP3-Audio um und bietet zwei Hauptmodi: Erzählung mit einer einzelnen Stimme und Mehrsprecher-Dialog mit zugewiesenen Sprachrollen.
Performance-Tags wie [laughing] (Lachen), [whispering] (Flüstern), [sighs] (Seufzen) und [short pause] (kurze Pause) ermöglichen eine detaillierte Kontrolle des Vortragsstils. Drei voreingestellte Richtungen — Natural (natürlich), Warm (warmherzig) und Cinematic (filmisch) — passen Tempo und Ton für verschiedene Inhaltstypen an, darunter Erklärvideos, Trailer und Einführungsmaterial.
Der Workflow folgt einer Schreiben-Anweisen-Rendern-Anhören-Herunterladen-Schleife mit MP3-Vorschau im Browser vor dem Export. Die Ausgaben dienen der Videobearbeitung, Podcast-Entwürfen, Werbemockups und Produktdemos.
Wie funktioniert Seed Audio?
Seed Audio arbeitet mit einem optimierten vierstufigen Workflow, der von den Text-to-Speech- und Text-to-Dialogue-Modellen von ElevenLabs angetrieben wird. Benutzer erstellen zunächst ein Quellskript — entweder einen einzelnen Erzählabsatz oder zwei bis vier Dialogabschnitte für Szenen mit mehreren Sprechern. Anschließend wählen sie Stimmen aus: einen einzelnen Sprecher für den Text-to-Speech-Modus oder verschiedene Stimmen für jeden Dialogabschnitt bei charaktergesteuerten Gesprächen. Leistungs-Tags wie [warmly](warm)、[curious](neugierig)、[laughing](lachend)、[whispering](flüsternd)、[sighs](seufzend)und [short pause](kurze Pause)steuern den emotionalen Ausdruck und das Tempo. Schließlich rendert das System eine MP3-Vorschau, die im Browser abgespielt werden kann, sodass eine sofortige Hörprobe vor dem Herunterladen möglich ist — für Videobearbeitungen, Podcast-Entwürfe, Werbemockups oder Produktdemos.
Vorteile von Seed Audio
Seed Audio fasst Text-to-Speech und die Generierung von Dialogen mit mehreren Sprechern in einem einzigen Browser-Tool auf Basis von ElevenLabs zusammen, sodass kein Wechsel zwischen verschiedenen Editoren mehr nötig ist. Leistungs-Tags wie [laughing], [whispering], [sighs] und [short pause] ermöglichen eine feinkörnige emotionale Steuerung in den Vortragsstilen Natural, Warm und Cinematic, während die sprecherweise Stimmenzuweisung glaubwürdige Charakterdialoge für Podcasts, Spielprototypen und Storyboard-Demos ermöglicht. Der enge Schreib-Regie-Rendering-Hören-Download-Zyklus produziert in Sekunden veröffentlichungsreife MP3s, allerdings bleibt der Workflow auf ElevenLabs' Stimmbibliothek beschränkt, ohne individuelles Stimmtraining, API-Zugriff oder Stapelverarbeitung, und der jährliche Preis von 668 US-Dollar liegt über der Schwelle für gelegentliche Experimente.
Vor- und Nachteile von Seed Audio
Vorteile
- Kombiniert TTS (Text-to-Speech) und Dialoggenerierung in einem Tool
- Leistungs-Tags steuern Emotion und Vortrag
- Mehrstimmige Dialogszenen mit Zuweisung von Sprecherrollen
- Schnelle MP3-Vorschau und Download im Browser
- Drei Vortragsstile: Natural, Warm, Cinematic
Nachteile
- Erfordert ein ElevenLabs-Konto für die Generierung
- Credit-basiertes Preismodell schränkt die Nutzung ein
- Nur Audio-Ausgabe, keine Video-Synchronisation
- Kein benutzerdefiniertes Voice-Cloning erwähnt
- Nur webbasiert, keine Offline-Funktion
Kernfunktionen von Seed Audio
Text-to-Speech-Erzeugung
Erzeugt Einzelerzähler-Voiceovers aus Skripten, Aufhängern, Erklärungen und kurzen Werbeeinspielungen mit klarer, natürlicher Wiedergabe.
Text-zu-Dialog-Erzeugung
Erstellt Gespräche mit mehreren Sprechern, indem jeder Runde verschiedene Stimmen zugewiesen werden, für Demos, Podcasts, Spiele und Storyboards.
Performance-Tags
Steuert die Stimmwiedergabe durch Inline-Tags wie [laughing] (Lachen), [whispering] (Flüstern), [sighs] (Seufzen) und [short pause] (kurze Pause) für ausdrucksstarke Kontrolle.
Vortragsstil-Voreinstellungen
Bietet drei voreingestellte Stile: Natural für klare Erzählung, Warm für freundliche Erklärungen, Cinematic für dramatisches Tempo.
Sprachauswahl pro Runde
Ermöglicht die individuelle Sprachzuweisung pro Dialogrunde und ermöglicht glaubwürdige Charakterwechsel in Szenen mit mehreren Sprechern.
MP3-Vorschau und Download
Rendert Audio in MP3 mit Wiedergabe im Browser und stellt herunterladbare Dateien für Videobearbeitungen, Podcast-Entwürfe und Demos bereit.
Anwendungsfälle von Seed Audio
- Content-Ersteller: Generieren Sie Voiceovers für Videoschnitte, Trailer und Storyboards mit expressiven Delivery-Tags
- Podcaster: Produzieren Sie Podcast-Entwürfe und Multi-Sprecher-Dialog-Episoden mit Multi-Voice-Dialoggenerierung
- Werbetreibende: Erstellen Sie Anzeigen-Mockups und Produktdemo-Voiceovers mit warmen, kinoreifen oder natürlichen Delivery-Stilen
- Spieleentwickler: Generieren Sie Charakterdialoge und narrative Voiceovers für Spielprototypen und Storyboards
- Videoeditoren: Produzieren Sie schnelle Voiceover-Entwürfe für Rohschnitte, Kundenreviews und finale Videoexporte
FAQs von Seed Audio
Was ist Seed Audio?
Seed Audio ist ein KI-gestütztes Tool zur Sprachsynthese (Text-to-Speech) und Text-zu-Dialog-Konvertierung, das auf ElevenLabs-Technologie basiert und in die NanoPhoto-Plattform integriert ist. Es wandelt geschriebene Skripte in gesprochenes Audio um, mit ausdrucksstarken Performance-Tags, Multi-Voice-Dialogunterstützung und schneller MP3-Vorschau. Benutzer schreiben oder fügen ein Skript ein, wählen eine Stimme, fügen optional Regieanweisungen hinzu und generieren in Sekundenschnelle hörbares Audio, ohne den Browser verlassen zu müssen.
Was ist der Unterschied zwischen Text-to-Speech und Text-to-Dialogue?
Text-to-Speech (TTS) erzeugt einen einzelnen Sprecher-Kommentar aus einem Textblock, ideal für Erklärvideos, Werbeeinlesungen und Sprachdrafts. Text-to-Dialogue weist verschiedenen Sprecherwechseln in einem Skript unterschiedliche Stimmen zu und unterstützt Mehrsprechersituationen für Podcasts, Spieldialoge, Demos und Storyboards. Der Dialogmodus akzeptiert auch Performance-Tags pro Sprecherwechsel, sodass die Darbietung jedes Charakters unabhängig gesteuert werden kann.
Welche Performance-Tags werden unterstützt?
Seed Audio erkennt Tags wie [laughing], [whispering], [sighs], [short pause], [warmly], [curious] und weitere, die den emotionalen Ton und das Tempo der Ausgabe steuern. Diese Tags werden direkt an der Stelle in den Skripttext eingefügt, an der sich die Darbietung ändern soll. Sie funktionieren sowohl im TTS- als auch im Dialogmodus und geben den Benutzern eine feine Kontrolle darüber, wie eine Zeile klingt, ohne dass eine externe Audiobearbeitung erforderlich ist.
Wie funktioniert die Preisgestaltung von Seed Audio?
Seed Audio verwendet ein kreditbasiertes Preismodell, bei dem jede Audiogenerierung 1 Kredit kostet. Kredite werden über die NanoPhoto-Plattform erworben und gelten für die gesamte Produktsuite. Dieses Pay-per-Generation-Modell eignet sich für Benutzer mit variablen Arbeitslasten, von gelegentlichen Sprachdrafts bis hin zur Massenproduktion von Dialogen, ohne dass eine monatliche Abonnementverpflichtung erforderlich ist.
Für wen ist Seed Audio gedacht?
Seed Audio richtet sich an Content-Ersteller, Videobearbeiter, Podcaster, Spieleentwickler und Produktteams, die schnell veröffentlichbare Sprach-Assets benötigen. Es passt in Arbeitsabläufe, bei denen Geschwindigkeit zählt, wie Werbemockups, Tutorial-Voiceovers, Charakterdialoge für Indie-Spiele und Podcast-Entwurfsaufnahmen. Benutzer, die sonst für jedes kurze Skript ein dediziertes Audiostudio öffnen müssten, können dieselbe Aufgabe in einem Bruchteil der Zeit erledigen.
Welche Audioformate gibt Seed Audio aus?
Seed Audio erzeugt MP3-Dateien, die direkt im Browser vorgehört und für Videobearbeitungssoftware, Podcast-Produktionstools, Spiele-Engines und Präsentationsfolien heruntergeladen werden können. MP3 wurde als Ausgabeformat aufgrund seiner Ausgewogenheit zwischen Dateigröße und Audioqualität gewählt und eignet sich sowohl für schnelle Entwürfe als auch für finale Assets.
Wie schneidet Seed Audio im Vergleich zu eigenständigen TTS-Tools ab?
Im Gegensatz zu eigenständigen TTS-Tools, die zwischen Anwendungen für die Skriptbearbeitung, Sprachauswahl und Audioexport wechseln müssen, hält Seed Audio den gesamten Workflow innerhalb der NanoPhoto-Plattform. Benutzer schreiben, führen Regie, rendern, hören zu und laden in einer einzigen Oberfläche herunter. Das integrierte Performance-Tag-System und der Mehrsprecher-Dialogmodus machen separate Audiobearbeitungsdurchgänge für grundlegende Darbietungsanpassungen überflüssig und reduzieren die Iterationszeit pro Generierung von Minuten auf Sekunden.
So verwenden Sie Seed Audio
- Schreiben Sie das Ausgangsskript, indem Sie einen Voiceover-Absatz oder zwei bis vier Dialogabschnitte eingeben, oder vier Abschnitte, die auf natürlich klingende Sprache ausgerichtet sind.
- Wählen Sie Stimmen und Vortrag, indem Sie eine Erzählerstimme für die Text-to-Speech (TTS) auswählen oder jedem Dialogabschnitt eine andere Stimme für den Charakteraustausch zuweisen.
- Fügen Sie Performance-Tags wie [warmly] (herzlich), [curious] (neugierig), [laughing] (lachend) oder [short pause] (kurze Pause) hinzu, um den emotionalen Vortrag zu lenken und das Ergebnis inszeniert wirken zu lassen.
- Hören Sie sich das generierte MP3 im Browser zur Qualitätsprüfung an, laden Sie dann die Audiodatei für Videobearbeitungen, Podcast-Entwürfe, Werbemockups oder Produktdemos herunter.
Seed Audio Website-Verkehrsanalyse
Aktuelle Verkehrsinformationen
- Monatliche Besuche131.03K
- Absprungrate46.71%
- Seiten pro Besuch2.22
- Besuchsdauer00:01:13
- Globaler Rang312.86K
- Länder-/Regionsranking24.09K
Besuche im Laufe der Zeit
Verkehrsquelle
- Direkte: 59.44%
- Organische Suche: 20.39%
- Empfehlungen: 10.82%
- Generative KI: 3.31%
- Bezahlte Suche: 2.62%
- Social organisch: 2.55%
Top-Keywords
| Stichwort | Verkehr | Volumen | Kosten pro Klick |
|---|---|---|---|
| nano banana | 2.11K | 3.24M | $0.65 |
| nanophoto.ai | 670 | 750 | -- |
| nano banana pro | 640 | 653.89K | $1.23 |
| nanophoto | 550 | 560 | $1.11 |
| nano photo | 540 | 10 | -- |
Top-Regionen
| Region | Prozentsatz |
|---|---|
| China | 58.8% |
| Vereinigte Staaten | 3.72% |
| Ghana | 3.28% |
| Hongkong | 2.54% |
| Taiwan | 2.18% |