Seed Audio Kernfunktionen
Erzeugen Sie ausdrucksstarke KI-Sprachaufnahmen und Dialoge mit Seed Audio. Ein von ElevenLabs betriebenes Text-to-Speech-Tool mit Performance-Tags, Mehrstimmen-Auswahl und schneller MP3-Vorschau.

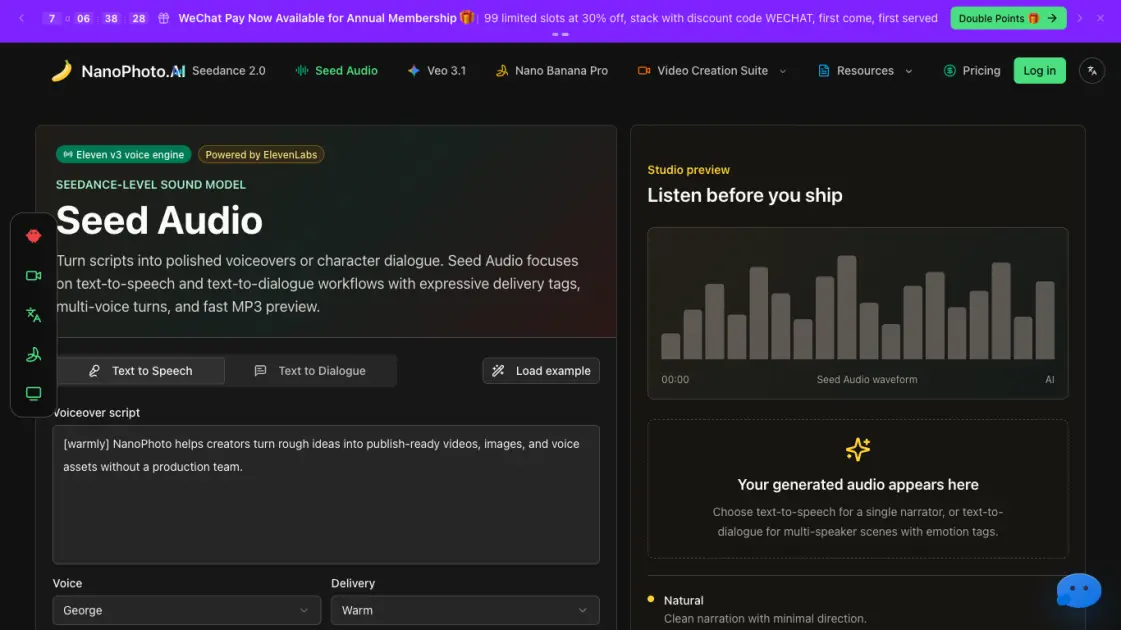
Kernfunktionen von Seed Audio
Text-to-Speech-Erzeugung
Erzeugt Einzelerzähler-Voiceovers aus Skripten, Aufhängern, Erklärungen und kurzen Werbeeinspielungen mit klarer, natürlicher Wiedergabe.
Text-zu-Dialog-Erzeugung
Erstellt Gespräche mit mehreren Sprechern, indem jeder Runde verschiedene Stimmen zugewiesen werden, für Demos, Podcasts, Spiele und Storyboards.
Performance-Tags
Steuert die Stimmwiedergabe durch Inline-Tags wie [laughing] (Lachen), [whispering] (Flüstern), [sighs] (Seufzen) und [short pause] (kurze Pause) für ausdrucksstarke Kontrolle.
Vortragsstil-Voreinstellungen
Bietet drei voreingestellte Stile: Natural für klare Erzählung, Warm für freundliche Erklärungen, Cinematic für dramatisches Tempo.
Sprachauswahl pro Runde
Ermöglicht die individuelle Sprachzuweisung pro Dialogrunde und ermöglicht glaubwürdige Charakterwechsel in Szenen mit mehreren Sprechern.
MP3-Vorschau und Download
Rendert Audio in MP3 mit Wiedergabe im Browser und stellt herunterladbare Dateien für Videobearbeitungen, Podcast-Entwürfe und Demos bereit.
Anwendungsfälle von Seed Audio
- Content-Ersteller: Generieren Sie Voiceovers für Videoschnitte, Trailer und Storyboards mit expressiven Delivery-Tags
- Podcaster: Produzieren Sie Podcast-Entwürfe und Multi-Sprecher-Dialog-Episoden mit Multi-Voice-Dialoggenerierung
- Werbetreibende: Erstellen Sie Anzeigen-Mockups und Produktdemo-Voiceovers mit warmen, kinoreifen oder natürlichen Delivery-Stilen
- Spieleentwickler: Generieren Sie Charakterdialoge und narrative Voiceovers für Spielprototypen und Storyboards
- Videoeditoren: Produzieren Sie schnelle Voiceover-Entwürfe für Rohschnitte, Kundenreviews und finale Videoexporte