Seed Audio Einführung
Erzeugen Sie ausdrucksstarke KI-Sprachaufnahmen und Dialoge mit Seed Audio. Ein von ElevenLabs betriebenes Text-to-Speech-Tool mit Performance-Tags, Mehrstimmen-Auswahl und schneller MP3-Vorschau.

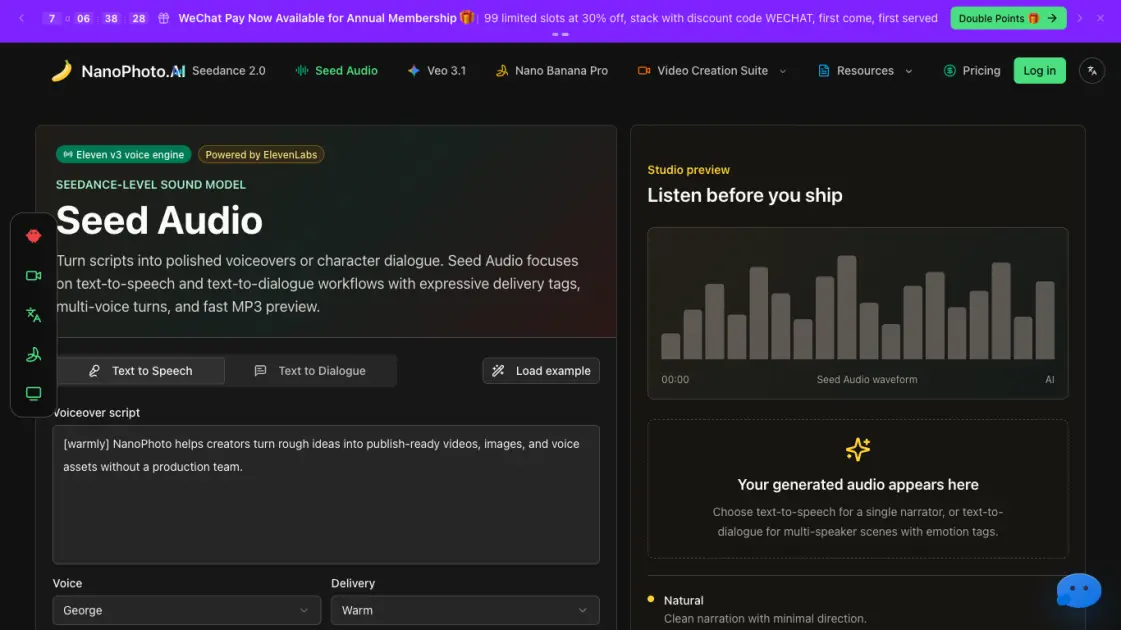
Was ist Seed Audio
Seed Audio ist ein Text-to-Speech- und Dialoggenerierungstool, das auf der ElevenLabs-Infrastruktur basiert und über die NanoPhoto-Plattform zugänglich ist. Der Dienst wandelt geschriebene Skripte in MP3-Audio um und bietet zwei Hauptmodi: Erzählung mit einer einzelnen Stimme und Mehrsprecher-Dialog mit zugewiesenen Sprachrollen.
Performance-Tags wie [laughing] (Lachen), [whispering] (Flüstern), [sighs] (Seufzen) und [short pause] (kurze Pause) ermöglichen eine detaillierte Kontrolle des Vortragsstils. Drei voreingestellte Richtungen — Natural (natürlich), Warm (warmherzig) und Cinematic (filmisch) — passen Tempo und Ton für verschiedene Inhaltstypen an, darunter Erklärvideos, Trailer und Einführungsmaterial.
Der Workflow folgt einer Schreiben-Anweisen-Rendern-Anhören-Herunterladen-Schleife mit MP3-Vorschau im Browser vor dem Export. Die Ausgaben dienen der Videobearbeitung, Podcast-Entwürfen, Werbemockups und Produktdemos.
Wie funktioniert Seed Audio?
Seed Audio arbeitet mit einem optimierten vierstufigen Workflow, der von den Text-to-Speech- und Text-to-Dialogue-Modellen von ElevenLabs angetrieben wird. Benutzer erstellen zunächst ein Quellskript — entweder einen einzelnen Erzählabsatz oder zwei bis vier Dialogabschnitte für Szenen mit mehreren Sprechern. Anschließend wählen sie Stimmen aus: einen einzelnen Sprecher für den Text-to-Speech-Modus oder verschiedene Stimmen für jeden Dialogabschnitt bei charaktergesteuerten Gesprächen. Leistungs-Tags wie [warmly](warm)、[curious](neugierig)、[laughing](lachend)、[whispering](flüsternd)、[sighs](seufzend)und [short pause](kurze Pause)steuern den emotionalen Ausdruck und das Tempo. Schließlich rendert das System eine MP3-Vorschau, die im Browser abgespielt werden kann, sodass eine sofortige Hörprobe vor dem Herunterladen möglich ist — für Videobearbeitungen, Podcast-Entwürfe, Werbemockups oder Produktdemos.
Vorteile von Seed Audio
Seed Audio fasst Text-to-Speech und die Generierung von Dialogen mit mehreren Sprechern in einem einzigen Browser-Tool auf Basis von ElevenLabs zusammen, sodass kein Wechsel zwischen verschiedenen Editoren mehr nötig ist. Leistungs-Tags wie [laughing], [whispering], [sighs] und [short pause] ermöglichen eine feinkörnige emotionale Steuerung in den Vortragsstilen Natural, Warm und Cinematic, während die sprecherweise Stimmenzuweisung glaubwürdige Charakterdialoge für Podcasts, Spielprototypen und Storyboard-Demos ermöglicht. Der enge Schreib-Regie-Rendering-Hören-Download-Zyklus produziert in Sekunden veröffentlichungsreife MP3s, allerdings bleibt der Workflow auf ElevenLabs' Stimmbibliothek beschränkt, ohne individuelles Stimmtraining, API-Zugriff oder Stapelverarbeitung, und der jährliche Preis von 668 US-Dollar liegt über der Schwelle für gelegentliche Experimente.
Vor- und Nachteile von Seed Audio
Vorteile
- Kombiniert TTS (Text-to-Speech) und Dialoggenerierung in einem Tool
- Leistungs-Tags steuern Emotion und Vortrag
- Mehrstimmige Dialogszenen mit Zuweisung von Sprecherrollen
- Schnelle MP3-Vorschau und Download im Browser
- Drei Vortragsstile: Natural, Warm, Cinematic
Nachteile
- Erfordert ein ElevenLabs-Konto für die Generierung
- Credit-basiertes Preismodell schränkt die Nutzung ein
- Nur Audio-Ausgabe, keine Video-Synchronisation
- Kein benutzerdefiniertes Voice-Cloning erwähnt
- Nur webbasiert, keine Offline-Funktion