Seed Audio - Herramienta IA de texto a voz y generación de diálogos

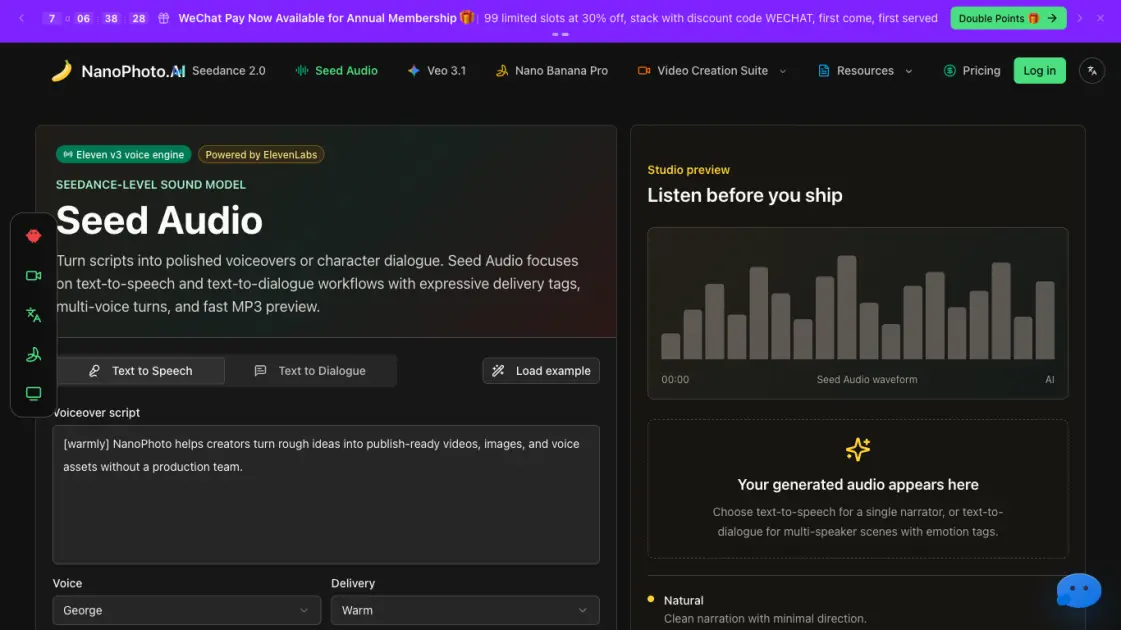
¿Qué es Seed Audio?
Seed Audio es una herramienta de conversión de texto a voz y generación de diálogos construida sobre la infraestructura de ElevenLabs, accesible a través de la plataforma NanoPhoto. El servicio convierte guiones escritos en audio MP3 con dos modos principales: narración de una sola voz y diálogo con múltiples locutores con asignación de turnos de voz.
Etiquetas de interpretación como [laughing] (risa), [whispering] (susurro), [sighs] (suspiros) y [short pause] (pausa breve) proporcionan un control detallado sobre el estilo de locución. Tres direcciones predefinidas —Natural, Warm y Cinematic— ajustan el ritmo y el tono para diferentes tipos de contenido, como vídeos explicativos, avances y material de incorporación.
El flujo de trabajo sigue un ciclo de escribir-dirigir-renderizar-escuchar-descargar con vista previa de MP3 en el navegador antes de la exportación. El resultado sirve para edición de vídeo, borradores de podcasts, maquetas de anuncios y demostraciones de productos.
¿Cómo funciona Seed Audio?
Seed Audio funciona mediante un flujo de trabajo simplificado de cuatro pasos impulsado por los modelos de texto a voz (text-to-speech) y texto a diálogo (text-to-dialogue) de ElevenLabs. Los usuarios comienzan escribiendo un guion fuente: ya sea un solo párrafo de narración o de dos a cuatro turnos de diálogo para escenas con múltiples hablantes. Luego seleccionan voces: un solo narrador para el modo de texto a voz, o asignan voces distintas a cada turno de diálogo para conversaciones con personajes. Las etiquetas de interpretación como [warmly](con calidez)、[curious](con curiosidad)、[laughing](riendo)、[whispering](susurrando)、[sighs](suspirando)y [short pause](pausa breve)dirigen la entrega emocional y el ritmo. Finalmente, el sistema genera una vista previa en MP3 reproducible en el navegador, lo que permite una audición inmediata antes de descargar para ediciones de video, borradores de podcast, maquetas de anuncios o demostraciones de productos.
Beneficios de Seed Audio
Seed Audio consolida la síntesis de texto a voz y la generación de diálogos con múltiples hablantes en una sola herramienta de navegador impulsada por ElevenLabs, eliminando la necesidad de cambiar entre editores separados. Las etiquetas de interpretación como [laughing], [whispering], [sighs] y [short pause] proporcionan un control emocional granular en los estilos de expresión Natural, Warm y Cinematic, mientras que la asignación de voz por turno permite intercambios creíbles entre personajes para podcasts, prototipos de juegos y demostraciones de guiones gráficos. El ciclo integrado de escritura-dirección-renderizado-escucha-descarga produce MP3 publicables en segundos, aunque el flujo de trabajo sigue limitado a la biblioteca de voces de ElevenLabs sin entrenamiento de voz personalizado, acceso a API ni procesamiento por lotes, y el precio anual de 668 dólares supera el umbral de la experimentación casual.
Pros y contras de Seed Audio
Ventajas
- Combina TTS (conversión de texto a voz) y generación de diálogos en una sola herramienta
- Las etiquetas de rendimiento controlan la emoción y la expresión
- Escenas de diálogo con múltiples voces y asignación de turnos
- Vista previa rápida y descarga de MP3 en el navegador
- Tres estilos de expresión: Natural, Warm, Cinematic
Desventajas
- Requiere una cuenta de ElevenLabs para generar
- El modelo de precios basado en créditos limita el uso
- Solo salida de audio, sin sincronización de video
- No se menciona la clonación de voz personalizada
- Solo versión web, sin capacidad offline
Características principales de Seed Audio
Generación de voz a partir de texto
Produce voces en off de un solo narrador a partir de guiones, ganchos, explicaciones y lecturas de anuncios cortos con una entonación limpia y natural.
Generación de diálogos a partir de texto
Crea conversaciones con múltiples hablantes asignando voces distintas a cada turno para demostraciones, podcasts, juegos y guiones gráficos.
Etiquetas de interpretación
Dirige la entonación vocal mediante etiquetas en línea como [laughing] (risa), [whispering] (susurro), [sighs] (suspiro) y [short pause] (pausa breve) para un control expresivo.
Preestablecidos de estilo de entonación
Ofrece tres estilos preestablecidos: Natural para narración limpia, Warm para explicaciones amigables, Cinematic para un ritmo dramático.
Selección de voz por turno
Permite asignar voces individuales a cada turno de diálogo, logrando intercambios creíbles entre personajes en escenas con múltiples hablantes.
Vista previa y descarga en MP3
Convierte el audio a MP3 con reproducción en el navegador y ofrece archivos descargables para ediciones de vídeo, borradores de podcasts y demostraciones.
Casos de uso de Seed Audio
- Creadores de contenido: Generen locuciones para ediciones de video, avances y guiones gráficos con etiquetas de entrega expresivas
- Podcasters: Produzcan borradores de podcasts y episodios de diálogo multi-voz usando generación de diálogo multi-voz
- Anunciantes: Creen maquetas de anuncios y locuciones de demostración de productos con estilos de entrega cálidos, cinematográficos o naturales
- Desarrolladores de juegos: Generen diálogos de personajes y locuciones narrativas para prototipos de juegos y guiones gráficos
- Editores de video: Produzcan borradores rápidos de locuciones para cortes preliminares, revisiones de clientes y exportaciones finales de video
Preguntas frecuentes de Seed Audio
¿Qué es Seed Audio?
Seed Audio es una herramienta de conversión de texto a voz (Text-to-Speech) y texto a diálogo impulsada por IA, basada en la tecnología de ElevenLabs e integrada en la plataforma NanoPhoto. Convierte guiones escritos en audio hablado con etiquetas de interpretación expresivas, soporte para diálogos con múltiples voces y vista previa rápida en MP3. Los usuarios escriben o pegan un guion, seleccionan una voz, opcionalmente añaden indicaciones de actuación y generan audio escuchable en segundos sin salir del navegador.
¿Cuál es la diferencia entre texto a voz y texto a diálogo?
Texto a voz (TTS) genera la locución de un solo narrador a partir de un bloque de texto, ideal para vídeos explicativos, lecturas de anuncios y borradores de locución. Texto a diálogo asigna diferentes voces a los distintos turnos de un guion, permitiendo conversaciones con múltiples interlocutores para pódcasts, diálogos de juegos, demos y storyboards. El modo diálogo también acepta etiquetas de interpretación por turno, de modo que la actuación de cada personaje puede dirigirse de forma independiente.
¿Qué etiquetas de interpretación se admiten?
Seed Audio reconoce etiquetas como [laughing], [whispering], [sighs], [short pause], [warmly], [curious] y otras que dirigen el tono emocional y el ritmo de la salida. Estas etiquetas se insertan directamente en el texto del guion en el punto donde debe cambiar la interpretación. Funcionan tanto en modo TTS como en modo diálogo, dando a los usuarios un control preciso sobre cómo suena una línea sin necesidad de edición de audio externa.
¿Cómo funciona el precio de Seed Audio?
Seed Audio utiliza un modelo de precios basado en créditos, donde cada generación de audio cuesta 1 crédito. Los créditos se compran a través de la plataforma NanoPhoto y se aplican a toda la suite de productos. Este modelo de pago por generación se adapta a usuarios con cargas de trabajo variables, desde borradores de locución ocasionales hasta producción de diálogos de alto volumen, sin necesidad de una suscripción mensual.
¿Para quién está diseñado Seed Audio?
Seed Audio está dirigido a creadores de contenido, editores de vídeo, podcasteros, desarrolladores de juegos y equipos de producto que necesitan activos de voz rápidos y publicables. Encaja en flujos de trabajo donde la velocidad importa, como maquetas de anuncios, locuciones de tutoriales, diálogos de personajes para juegos independientes y grabaciones de borradores de pódcasts. Los usuarios que antes abrían un estudio de audio dedicado para cada guion corto pueden completar la misma tarea en una fracción del tiempo.
¿Qué formatos de audio genera Seed Audio?
Seed Audio genera archivos MP3 que se pueden previsualizar directamente en el navegador y descargar para usar en software de edición de vídeo, herramientas de producción de pódcasts, motores de juegos y presentaciones. Se eligió MP3 como formato de salida por su equilibrio entre tamaño de archivo y calidad de audio, lo que lo hace práctico tanto para borradores rápidos como para activos finales.
¿Cómo se compara Seed Audio con las herramientas TTS independientes?
A diferencia de las herramientas TTS independientes que requieren cambiar entre aplicaciones para editar el guion, seleccionar la voz y exportar el audio, Seed Audio mantiene todo el flujo de trabajo dentro de la plataforma NanoPhoto. Los usuarios escriben, dirigen, renderizan, escuchan y descargan en una sola interfaz. El sistema integrado de etiquetas de interpretación y el modo de diálogo multi-voz eliminan la necesidad de sesiones de edición de audio separadas para ajustes básicos de actuación, reduciendo el tiempo de iteración de minutos a segundos por generación.
Cómo utilizar Seed Audio
- Escribe el guion fuente introduciendo un párrafo de locución o de dos a cuatro turnos de diálogo, o cuatro turnos centrados en un habla natural.
- Elige voces y estilo seleccionando una voz de narrador para conversión de texto a voz (TTS) o asignando una voz diferente a cada turno de diálogo para intercambio entre personajes.
- Añade etiquetas de interpretación como [warmly] (con calidez), [curious] (con curiosidad), [laughing] (riendo) o [short pause] (pausa breve) para guiar la entrega emocional y lograr un resultado más dirigido.
- Previsualiza el MP3 generado en el navegador para verificar la calidad, luego descarga el archivo de audio para ediciones de video, borradores de podcast, maquetas de anuncios o demostraciones de producto.
Seed Audio Análisis del tráfico web
Información de tráfico más reciente
- Visitas Mensuales131.03K
- Porcentaje de rebote46.71%
- Páginas por visita2.22
- Duración de la visita00:01:13
- Posición Mundial312.86K
- Clasificación de país/región24.09K
Visitas a lo largo del tiempo
Fuentes de tráfico
- Directo: 59.44%
- Búsqueda orgánica: 20.39%
- Referencias: 10.82%
- IA Generativa: 3.31%
- Búsqueda de pago: 2.62%
- Social orgánico: 2.55%
Palabras clave principales
| Palabra clave | Tráfico | Volumen | Costo por click |
|---|---|---|---|
| nano banana | 2.11K | 3.24M | $0.65 |
| nanophoto.ai | 670 | 750 | -- |
| nano banana pro | 640 | 653.89K | $1.23 |
| nanophoto | 550 | 560 | $1.11 |
| nano photo | 540 | 10 | -- |
Regiones principales
| Región | Porcentaje |
|---|---|
| China | 58.8% |
| Estados Unidos | 3.72% |
| Ghana | 3.28% |
| Hong Kong | 2.54% |
| Taiwán | 2.18% |