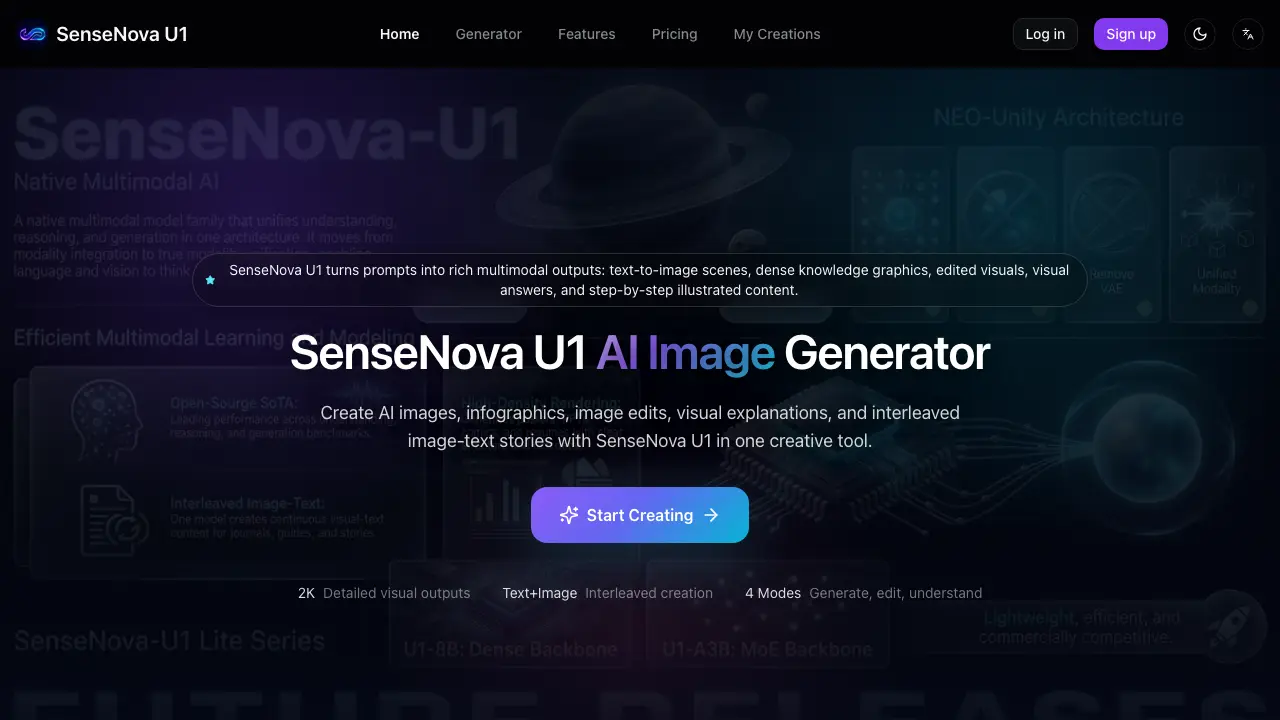
SenseNova U1 crée des images IA, des infographies et des histoires

Qu'est-ce que SenseNova U1
SenseNova U1 est un créateur multimodal piloté par l'IA qui transforme des invites textuelles en productions visuelles à haute densité. Les utilisateurs peuvent générer des scènes originales, des affiches et des illustrations conceptuelles, puis les affiner grâce à une retouche d’image basée sur les invites, sans avoir besoin d’un logiciel de conception complexe. La plateforme propose également un raisonnement visuel : les images téléchargées peuvent être interrogées pour obtenir des détails, ce qui permet des modifications précises ou des graphiques explicatifs. Un mode infographique dédié structure les informations complexes en cartes de connaissance claires et riches en libellés, tandis que le mode image‑texte en alternance prend en charge les tutoriels pas à pas, les bandes dessinées et les carnets de voyage. La résolution de sortie atteint 2 K, adaptée aux supports marketing, aux diapositives de présentation et aux documents éducatifs. Le flux de travail suit quatre étapes simples — sélection de la tâche, rédaction de l’invite, génération et révision — permettant aux créateurs, enseignants et marketeurs de produire rapidement et de façon itérative du contenu visuel soigné.
Comment fonctionne SenseNova U1
SenseNova U1 traite les requêtes des utilisateurs via une chaîne d'IA multimodale qui analyse d'abord les instructions textuelles, puis les associe à des concepts visuels à l'aide d'un modèle de diffusion texte‑à‑image. Lorsqu'une image est téléchargée, le système extrait les caractéristiques visuelles, applique des transformations guidées par le prompt et régénère le résultat édité. Pour les tâches de compréhension visuelle, le modèle effectue une analyse d'image, génère une représentation sémantique et répond aux questions en s'appuyant sur ce raisonnement. La plateforme assemble également les images générées et le texte associé en séquences alternées, permettant de créer des infographies, des tutoriels et des story‑boards. Tout au long du processus, les utilisateurs affinent les résultats en ajustant les prompts ou en modifiant les sorties avant la révision finale.
Avantages de SenseNova U1
SenseNova U1 est un créateur multimodal alimenté par l'IA qui transforme des prompts textuels en images détaillées, visuels modifiables, infographies structurées et séquences imbriquées image‑texte. En proposant quatre modes distincts — génération, édition, compréhension visuelle et storytelling — il rationalise les flux de travail des designers, éducateurs et marketeurs qui ont besoin de contenus visuels rapides comme des affiches, des tutoriels, des concepts de produits ou des cartes de connaissances. L'édition basée sur les prompts supprime le besoin de logiciels de conception complexes, tandis que le Q&A visuel permet de raisonner sur des images existantes pour affiner les résultats. Un rendu à haute densité génère des graphiques prêts à être présentés, et la plateforme encourage une révision itérative afin d'assurer l'exactitude avant la publication.
Avantages et inconvénients de SenseNova U1
Points forts
- Génère des visuels texte‑à‑image et des infographies à partir d’instructions.
- Permet la retouche d’images via des consignes en langage naturel.
- Offre des fonctions de questions‑réponses visuelles et de raisonnement.
- Autorise le storytelling alternant images et texte pour des tutoriels ou bandes‑dessinées.
- Gère des graphiques de connaissances très denses pour les présentations.
Points faibles
- La création intercalée est qualifiée d’expérimentale et peut être instable.
- Les détails fins du corps humain (visages, mains) nécessitent souvent une retouche manuelle.
- La typographie et le positionnement précis du texte peuvent être inexacts.
- Les scènes larges ou complexes donnent parfois des résultats plus faibles.
- Aucun tarif explicite n’est fourni, rendant l’estimation du coût difficile.
Fonctionnalités principales de SenseNova U1
Génération d'images IA
Crée des scènes détaillées, des concepts, des affiches et des illustrations à partir d'invites textuelles, permettant une production rapide d'éléments visuels pour le marketing, le storytelling et les supports pédagogiques.
Édition d'image basée sur les invites
Modifie les images téléchargées selon les instructions de l'utilisateur, offrant des changements de style, l'ajout ou la suppression d'objets et des ajustements de composition sans outils de conception manuels.
Compréhension visuelle & Q&R
Analyse les images, répond aux questions sur leur contenu et fournit le raisonnement, aidant les utilisateurs à affiner leurs concepts ou à extraire des informations pour les tâches créatives suivantes.
Création d'infographies et de graphiques de connaissances
Transforme des sujets complexes en visuels structurés à forte densité, avec sections étiquetées, hiérarchie et mise en page claire, idéaux pour présentations, rapports et ressources d'apprentissage.
Storytelling intercalé texte‑image
Génère des séquences où texte et image se succèdent, supportant tutoriels, bandes dessinées, carnets de voyage et guides illustrés qui mêlent flux narratif et détail visuel.
Cas d'utilisation de SenseNova U1
- Enseignants : Créez des tutoriels illustrés et des guides pas‑à‑pas avec des séquences image‑texte alternées pour les supports de cours.
- Marketers : Produisez des infographies très denses et des visuels type affiche qui résument des données complexes en une seule image partageable.
- Designers : Modifiez des concepts existants via des instructions prompt, en ajustant style, composition ou couleurs sans retouche manuelle.
- Chercheurs : Utilisez le Q&A visuel pour analyser des images scientifiques, extraire des détails et créer des schémas annotés pour vos publications.
- Créateurs de contenu : Assemblez des carrousels et des récits visuels riches en images pour les réseaux sociaux en combinant des scènes générées par IA avec des légendes concises.
FAQ de SenseNova U1
À quoi sert SenseNova U1 ?
SenseNova U1 est une plateforme alimentée par l’IA qui crée des images à partir d’instructions textuelles, produit des infographies riches en données, édite des visuels téléchargés, répond à des questions visuelles et génère des histoires image‑texte alternées pour des projets éducatifs, marketing et de design.
SenseNova U1 peut‑il générer des images à partir du texte ?
Oui. En fournissant une description claire de la scène souhaitée, du style, de la composition et des éventuelles étiquettes, SenseNova U1 synthétise une image haute résolution correspondant aux spécifications du prompt.
SenseNova U1 peut‑il créer des infographies ?
Oui. L’outil transforme des sujets complexes en graphiques de connaissance structurés et denses, ajoutant automatiquement sections, libellés et hiérarchie visuelle pour produire des infographies au look professionnel, adaptées aux présentations ou aux supports pédagogiques.
Puis‑je modifier une image existante avec SenseNova U1 ?
Oui. Après avoir téléchargé une image de référence, vous pouvez donner des consignes basées sur un prompt — par exemple changer les couleurs, ajouter des objets ou modifier la composition — et SenseNova U1 ajustera l’image en conséquence.
SenseNova U1 peut‑il répondre à des questions sur une image ?
Oui. Grâce au raisonnement visuel, le système analyse l’image importée, interprète ses éléments et fournit des réponses concises sur les objets, la mise en page, le texte ou les détails contextuels.
Qu’entend‑on par génération d’image‑texte entrelacée ?
La génération entrelacée signifie que SenseNova U1 peut produire une séquence où texte et images se succèdent, permettant la création de tutoriels illustrés, de carnets de voyage, de bandes‑dessinées ou de guides pas à pas dans un même flux de travail.
Quels prompts donnent les meilleurs résultats ?
Les prompts qui précisent clairement le sujet, le public cible, le style visuel, le format d’image, le texte requis et les détails de mise en page tendent à produire les sorties les plus précises et détaillées avec SenseNova U1.
Comment améliorer un résultat médiocre ?
Affinez le prompt en ajoutant des indications plus précises sur la composition, des références de style, des palettes de couleurs ou des consignes de placement du texte, puis regénérez ou utilisez le mode édition intégré pour peaufiner le résultat.
Existe‑t‑il des limites de sortie à connaître ?
SenseNova U1 peut avoir du mal avec des détails humains très fins, une typographie très petite ou des séquences visuelles extrêmement longues ; il est recommandé de vérifier et d’ajuster manuellement ces parties avant publication.
À qui s’adresse principalement SenseNova U1 ?
La plateforme vise les créateurs, designers, éducateurs, marketeurs, chercheurs et petites équipes qui ont besoin de contenu visuel multimodal rapide sans maîtriser des logiciels de conception complexes.
Supplément : comment SenseNova U1 gère‑t‑il le texte à l’intérieur des images ?
Bien que le moteur puisse insérer du texte dans les graphiques générés, l’orthographe, la cohérence des polices et la justesse des libellés ne sont pas garanties ; les utilisateurs doivent vérifier et corriger tout élément textuel avant l’utilisation finale.
Supplément : SenseNova U1 peut‑il être utilisé pour des visuels sur les réseaux sociaux ?
Oui. L’outil peut créer des affiches, des images carrousel et de courtes histoires visuelles optimisées pour des plateformes comme Instagram, Twitter et LinkedIn, aidant les utilisateurs à maintenir une identité visuelle cohérente.
Comment utiliser SenseNova U1
SenseNova U1 transforme les consignes textuelles en visuels multimodaux, offrant la génération d'images, la création d'infographies, l'édition basée sur les prompts, le Q&A visuel et la narration alternée image‑texte pour des projets créatifs et pédagogiques.
Choisissez la tâche souhaitée — texte‑vers‑image, infographie, édition d'image, Q&A visuel ou histoire alternée — en cliquant sur le mode correspondant dans l'interface du générateur.
Rédigez un prompt clair précisant le sujet, le public, le style visuel, la composition, les libellés et les éventuels éléments textuels requis, puis soumettez‑le dans la zone de saisie.
Lancez le processus de génération ; la plateforme rend l'image, le visuel édité, le graphique de connaissances ou la séquence illustrée selon la description fournie.
Examinez le rendu en vérifiant la exactitude factuelle, la cohérence de la mise en page, la lisibilité du texte et les détails visuels ; utilisez les contrôles d'édition intégrés ou affinez le prompt pour une amélioration itérative.
Exportez les actifs visuels finaux dans le format souhaité et intégrez‑les aux présentations, tutoriels, supports marketing ou réseaux sociaux, en respectant la charte graphique et les règles de droits d'auteur.
SenseNova U1 Analyse du trafic sur le site web
Dernières informations trafic
- Visites mensuelles1.62K
- Taux de rebond35.78%
- Pages par visite1.75
- Durée de la visite00:00:01
- rang global9.13M
- Classement des pays/régions3.35M
Visites au fil du temps
Mots-clés principaux
| Mot-clé | Trafic | Le volume | Coût par clic |
|---|---|---|---|
| sensenovau1 | 160 | 170 | -- |
| sensenova u1 | 150 | 3.83K | -- |
| senovn | 150 | 300 | -- |
| sensenova | 70 | 4.12K | -- |
| sense nova | 60 | 720 | -- |
Principales régions
| Région | Pourcentage |
|---|---|
| États-Unis | 89.36% |
| Maroc | 5.97% |
| Inde | 4.67% |